BigQuery
This guide describes how Mixpanel exports your data into a customer-managed Google BigQuery (opens in a new tab) dataset.
Design

For events data, we create a single table called mp_master_event and store all external properties inside the properties column in JSON type. Users can extract properties using JSON functions. See Query Data for more details.
For user profiles and identity mappings, we create new tables mp_people_data_* and mp_identity_mappings_data_* with a random suffix every time and then update views mp_people_data_view and mp_identity_mappings_data_view accordingly to use the latest table. Always use the views instead of the actual tables, as we do not immediately delete old tables, and you may end up using outdated data.
Export logs are maintained in the mp_nessie_export_log table within BigQuery. This table provides detailed information such as export times, date ranges (from date & to date), and the number of rows exported. This data allows for effective monitoring and auditing of the data export processes.
Important: Please do not modify the schema of tables generated by Mixpanel. Altering the table schema can cause the pipeline to fail to export due to schema mismatches.
Setting BigQuery Permissions
Please follow these steps to share permissions with Mixpanel and create json pipelines.
Step 1: Create a Dataset
Create a dataset in your BigQuery to store the Mixpanel data.
Step 2: Grant Permissions to Mixpanel
Note: If your organization uses domain restriction constraint (opens in a new tab) you will have to update the policy to allow Mixpanel domain
mixpanel.comand Google Workspace customer ID:C00m5wrjz.
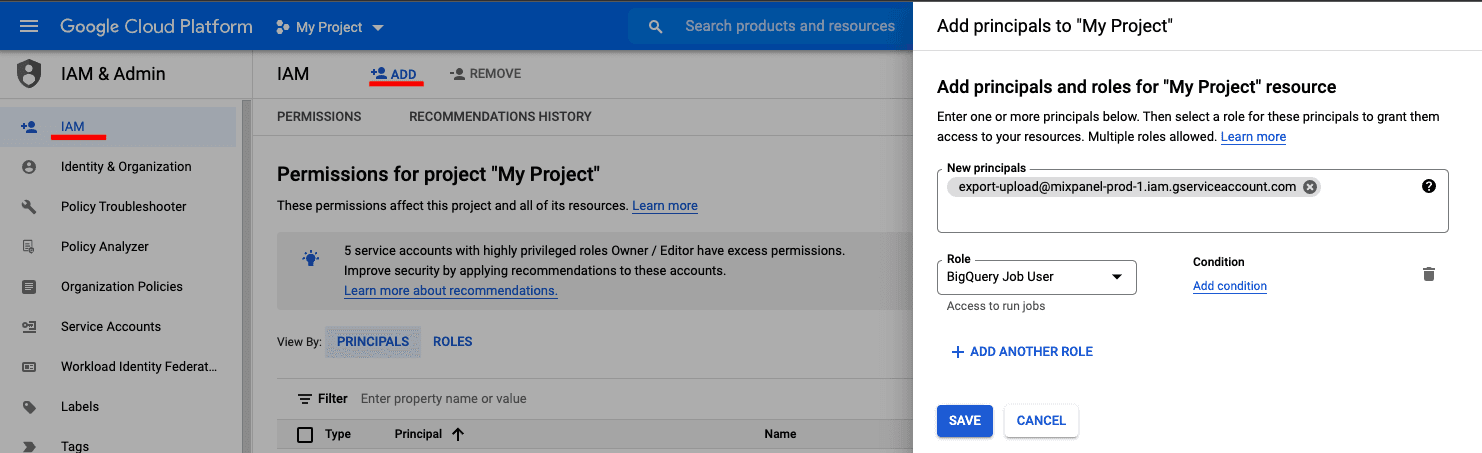
Mixpanel requires two permissions to manage the dataset:
BigQuery Job User
- Navigate to IAM & Admin in your Google Cloud Console.
- Click + ADD to add principals
- Add new principle
export-upload@mixpanel-prod-1.iam.gserviceaccount.comand set the role asBigQuery Job User - Click the Save button.
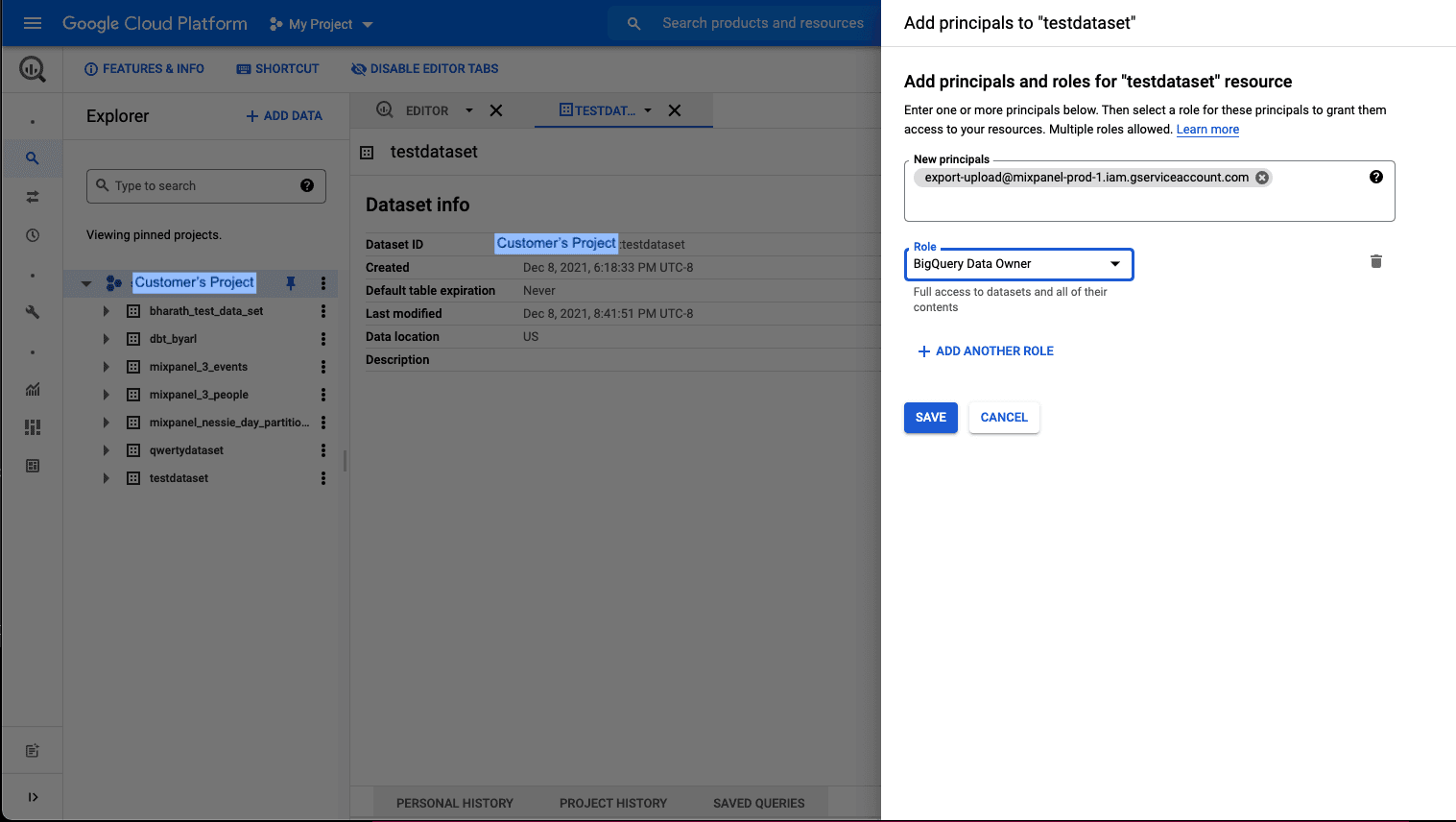
BigQuery Data Owner
- Go to BigQuery in your Google Cloud Console.
- Open the dataset intended for Mixpanel exports.
- Click on Sharing and Permissions in the drop down.
- In the Data Permissions window, click on Add Principal
- Add new principle
export-upload@mixpanel-prod-1.iam.gserviceaccount.comand set the role asBigQuery Data Owner, and save.
Step 3: Provide Necessary Details for Pipeline Creation
Refer to Step 2: Creating the Pipeline to create data pipeline via UI. You need to provide specific details to enable authentication and data export to BigQuery.
- GCP project ID: The project ID where BigQuery dataset is present
- Dataset name: Dataset created on the GCP project to which Mixpanel needs to export data
- GCP region: The region used for BigQuery
Partitioning
Data in the events table mp_master_event is partitioned based on the _PARTITIONTIME pseudo column (opens in a new tab) and in the project timezone.
Note: TIMEPARTITIONING should not be updated on the table. It will cause your export jobs to fail. Create a new table/view from this table for custom partitioning.
Query Data
This section provides examples of how to query data exported to BigQuery. Refer to BigQuery docs (opens in a new tab) for more details about using JSON functions to query properties.
Get the Number of Events Each Day
To verify the completeness of the export process, use the following SQL query to count events per day:
SELECT
_PARTITIONTIME AS pt,
COUNT(*)
FROM
`<your gcp project>.<your dataset>.mp_master_event`
WHERE
DATE(_PARTITIONTIME) <= "2024-05-31"
AND DATE(_PARTITIONTIME) >= "2024-05-01"
GROUP BY
ptQuery identity mappings
When querying the identity mappings table, prioritize using the resolved_distinct_id over the non-resolved distinct_id whenever it is available. If a resolved_distinct_id is not available, you should revert to using the distinct_id from the existing people or events table.
Below is an example query that utilizes the identity mappings table. This query counts the number of events for each unique user in San Francisco within a specific date range.
SELECT
CASE
WHEN mappings.resolved_distinct_id IS NOT NULL THEN mappings.resolved_distinct_id
WHEN mappings.resolved_distinct_id IS NULL THEN events.distinct_id
END
AS resolved_distinct_id,
COUNT(*) AS count
FROM
`<your gcp project>.<your dataset>.mp_master_event` events
INNER JOIN
`<your gcp project>.<your dataset>.mp_identity_mappings_data_view` mappings
ON
events.distinct_id = mappings.distinct_id
AND JSON_VALUE(properties,'$."$city"') = "San Francisco"
AND DATE(events._PARTITIONTIME) <= "2024-05-31"
AND DATE(events._PARTITIONTIME) >= "2024-05-01"
GROUP BY
resolved_distinct_id
LIMIT
100This query demonstrates how to effectively use conditional logic and JSON functions within BigQuery to analyze user behavior based on geographic location. Additional filters on event properties can be added to refine the analysis, allowing for more detailed insights into specific user actions or behaviors.
Was this page useful?